Demlas Data and Metadata management system
Data & Metadata Publishing Workflow | Python Metadata Viewer | GeoNetwork Metadata Viewer | Analysis | Geospatial Web Services | References
The data and metadata publishing workflow is based on the methodology for automatic creation, validation and publication of geospatial metadata proposed by Kliment et al (2013) and previously implemented in another project Bordogna et al. (2016). The overall idea is schematically represented in Figure 1.
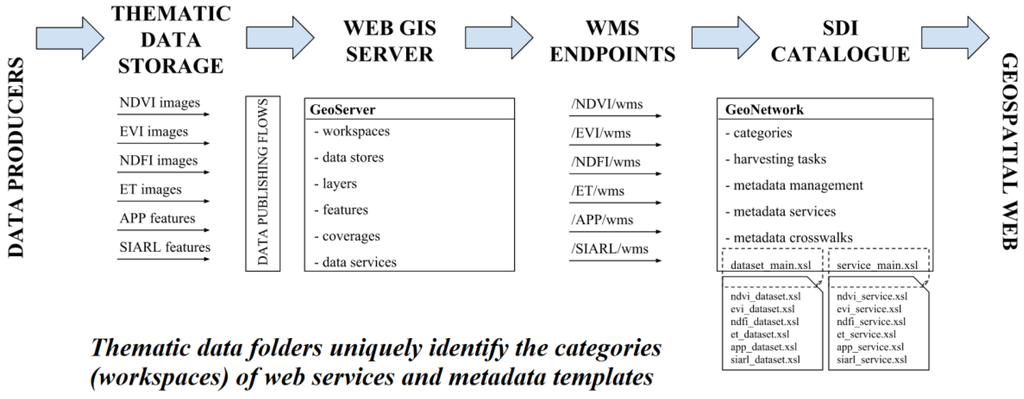
Figure 1. Schematic representation of the workflow designed to automate the process of GD and metadata publishing within an SDI (source: Bordogna et al, 2016).
Starting from the left hand side, the workflow inputs are historic / newly collected datasets provided by the producers (demlas stakeholders) by moving into predefined folder structure - THEMATIC DATA STORAGE - within the file system of the virtual machine deployed on the university cloud center (SRCE). Initially the historic data have been divided into the four thematic groups as follows:
1. Cadastral parcels - CP
2. Land cover - LC
3. Orthoimagery - OI
4. Elevation - EL
In order to publish the datasets available within the thematic data folders into a Web GIS server, data publishing flows have to be implemented and incorporated into the workflow. The research reported in Bordogna et al (2016) used Java based open source tool GeoBatch, however they addressed some drawbacks among which was a statement that the project is obsolete and complex to be customized by a project specific needs. Since the needs of the DEMLAS project required additional functionality as support of other Geoserver data source types and automatic creation of projection files for raster images, we decided to develop an in-house DATA PUBLISHING FLOWS using PHP language and Apache web server. The current pilot version of data publication flow reads the TIF files in a predefined data folder (e.g. /opt/demlas/cp/georef), writes project file (tiffilename.prj), creates coverage stores of a worldimage type on Web GIS server deployed by GeoServer opensource application and executes a harvesting task assigned to the data category.
Once the data are published on GeoServer they are made available via open APIs as Web Map Service (WMS), Web Feature Service (WFS) and Web Coverage Service (WCS) to be portrayed, downloaded and used (Cetl et al, 2016). In order to automate the next step of the workflow, which is to create geospatial metadata, an SDI catalogue is introduced. Basic (mostly dynamic) metadata are collected in the catalogue by use of harvesting tasks applied on e.g. WMS service endpoint which bears basic metadata about the service and dataset visualized as WMS Layers via it's capabilities document. Other metadata as e.g. Lineage, abstract, keyword set, etc. are defined in so called metadata templates created for each data theme, e.g. cadastral parcels -> georeferenced maps; using an online excel sheet. These metadata are later integrated into individual records during the harvesting task execution.
Related resources as e.g. georeferenced cadastral and related scanned map sheets are linked via a single metadata record providing the geospatial metadata. In addition, any other related data sources as e.g. additional info to cadastral parcels (KDKO) is described by individual metadata records linked to the root geospatial dataset metadata.
The metadata are finally made available for querying by users ofgeospatial web using Catalogue Service for Web (CSW) interface. Demlas has tested two pilot solutions, one using GeoNetwork opensource as a back-end catalogue and front-end client and pyCSW as only back-end CSW catalogue.